The Wild West of Jupyter

There's some wacky stuff in the Jupyter ecosystem. Still, one thing that really stood out for me was the extension of Jupyter notebooks into web development and their interaction with the JavaScript ecosystem. So web assembly is a thing, and you can run C and Rust code inside little isolated JavaScript sandboxes instances, maybe even from your CDN, so of course you want to compile Python in WASM. Now you're wondering, didn't Jupyter do some fancy refactoring a while ago? I wonder if I can put a webserver up there, too...
Behold JupyterLite:
Wow! Just what you always wanted: free notebook hosting! you can install packages, you can code, powered by this:
Comparing this with the standard architecture for Jupyter:
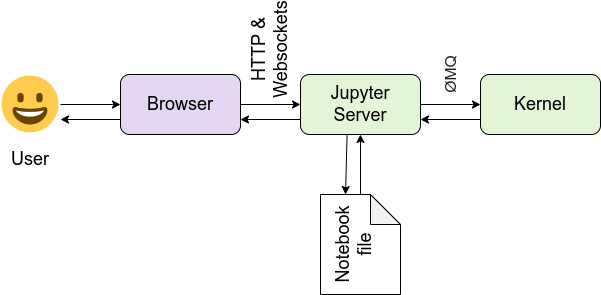
You see, one basically has to reimplement the server side of Jupyter in the browser. This is not a small task because Jupyter Server depends on more hefty libraries like ZeroMQ and Tornado, but presumably, compiling to WASM is useful.
I don't have an excellent knowledge of the history of the Jupyter project. Still, I remember this whole thing blowing up in about 2015 with the big split. The big split was a drive to make Jupyter language agnostic, which, as I understand, is more or less successful; nowadays, you can run R, Julia, and even C++ in a Jupyter notebook. It's not really appreciated how much the whole project has ballooned:
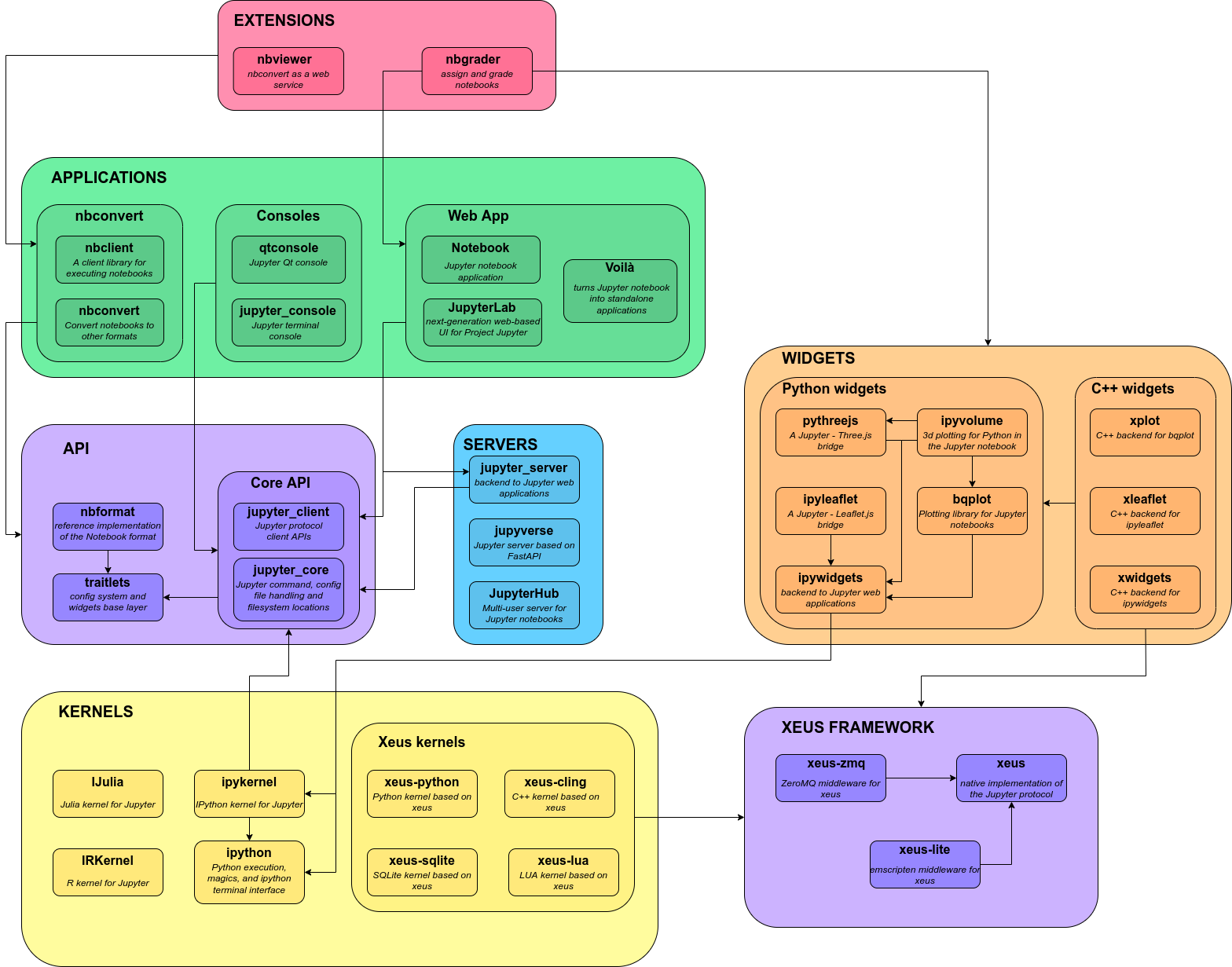
and that's just the offical projects! You probably know about related things like nbconvert, JupyterLab and IPython. There are some funny spin-of (besides jupyterlite) that you may or may not be aware of
Another exciting thing is that Colaboratory and VSCode have non-standard implementations of the client side of the Jupyter (ask me how I know). In fact there's a whole ecosystem (built on the ricketty foundation of ipywidgets) for web development with Jupyter: voila, Mercury and Solara aiming to compete streamlit for the affluent market consisting of data scientists who would literally prefer to do anything than write javascript.
My use case for Jupyter notebooks is primarily for exploratory data analysis and expository stuff. Early in my PhD, I had a few bad experiences with state preservation, which soured me to use it for more serious projects. You are probably aware that opinion is controversial. I like the literate programming approach of Rmarkdown/quarto (it supports Python now, so check it out) much more because it solves the issues with the non-transparent notebook blob of JSON in the ipynb format and allows better IDE integration. One direction of this is ipynb to ipynb; Jupyter has an equivalent for a while, nbconvert. It's only recently that py to ipynb has standardised on Jupytext (although there's also nbdev). It's interesting that Jupytext (it's used, for instance, in the VSCode implementation of notebooks) that it's not part of the core ecosystem. Is the whole project a horrible mess in scope creep, or is it a shining example of the power of open source? I don't know, but the Jupyter project has been shaped by the community's needs in unexpected ways.